Auth0 captcha — undone
Undone by 100 characters.
A path-length threshold cleanly separated real glyphs from cubic-Bézier noise. No ML.
Reverse-engineered Auth0's SVG-based captcha. A single statistical observation — text glyphs use short path definitions, decorative interference uses long ones — collapsed the entire defense to a 100-character heuristic.
§ The initial encounter
When I first encountered this SVG-based CAPTCHA system, it presented itself as a seemingly impenetrable wall of visual noise. Curved lines danced across the text, shadows created false depth, and stroke-based rendering made character recognition nearly impossible.
But every puzzle has its patterns, and every defense has its tells.
What appeared to be sophisticated obfuscation was actually a carefully orchestrated illusion — and like any good magic trick, once you understand the method, the mystery dissolves.
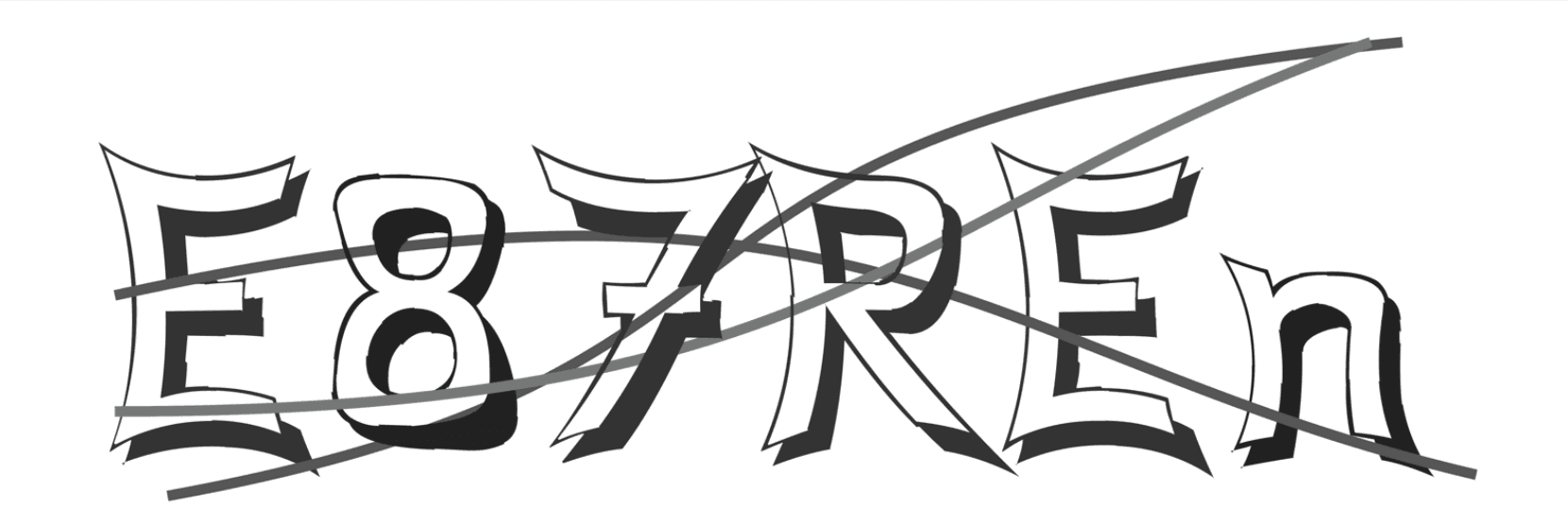
The original CAPTCHA: a maze of curves, shadows, and stroke-based rendering designed to confuse OCR systems.
§ The breakthrough moment
The first revelation came from a simple observation that would prove fundamental: I opened the SVG source and noticed something peculiar about the path definitions. The decorative curves sprawled across hundreds of characters of mathematical instructions, while actual text glyphs were remarkably concise. This wasn’t just a pattern — it was a fingerprint.
Think about it logically: a letter like ‘E’ or ‘8’ is geometrically simple. A few straight lines, maybe a curve or two. But those sweeping interference lines? They’re cubic Bézier curves with multiple control points, creating complex mathematical descriptions. The CAPTCHA’s attempt at complexity had inadvertently created a binary classification system.
§ Phase 1 — Path-length discovery
My first function, remove_cubic_bezier, leveraged this fundamental insight:
if len(d_attr) < 100: # text glyph, keep
pass
else: # decorative cubic Bézier, strip
root.remove(path)
The elegance here wasn’t in the code’s complexity, but in its simplicity. After analyzing dozens of CAPTCHAs, I discovered that legitimate character paths consistently stayed under 100 characters, while obfuscation elements exceeded it. This wasn’t guesswork — it was pattern recognition meeting statistical analysis.

After applying the path-length heuristic: the cubic Bézier curves are gone, but shadows and stroke effects remain.
§ Phase 2 — The shadow revelation
But removing the curves only revealed another layer of obfuscation. The text appeared multiple times, slightly offset, creating a shadow effect that confused OCR systems. This is where things got interesting.
I noticed the SVG was using ZM commands (MoveTo instructions) to create these shadows. Each shadow was essentially the same path, just starting from a slightly different position. The breakthrough came when I realized I could identify the “real” text by finding the primary pattern:
zm_int = zms[1][:3] # First three characters after ZM = primary position
This wasn’t just removing shadows — it was understanding the CAPTCHA’s rendering logic. The system was drawing the same character multiple times to create depth, but it had to maintain consistency in the base coordinates to keep the text readable for humans. That consistency became its vulnerability.
§ Phase 3 — The stroke-to-fill transformation
Here’s where I made a connection that tied everything together: the CAPTCHA was using stroke-based rendering (outlines) instead of filled characters. Why? Because strokes create more complex path definitions and are harder for basic OCR to read.
But this defensive choice actually provided another attack vector. By removing the stroke variations and converting to fills, I was essentially reversing the CAPTCHA’s own transformation process. The remove_transformations function didn’t just clean the SVG — it understood and inverted the obfuscation algorithm.

The final result: clean, filled characters ready for OCR processing — ‘E87REn’ extracted with perfect clarity.
§ The complete pipeline
The final implementation is beautifully straightforward:
def ocr(image_b64):
# load image
image_data = base64.b64decode(image_b64.split(",")[1])
svg_img = image_data.decode("utf-8")
# remove noise
svg = remove_cubic_bezier(svg_img) # Strip the curves
svg = remove_transformations(svg) # Eliminate shadows and normalize
png_data = cairosvg.svg2png(bytestring=svg) # Render clean version
return tesseract_ocr(png_data)
Three functions. ~80 lines of Python. No machine learning. No training data.
§ The intelligence behind the implementation
What makes this solution particularly clever isn’t just that it works — it’s that it demonstrates a deep understanding of multiple domains:
- Geometric intuition. Recognizing that text complexity has inherent limits was crucial. Letters must remain simple to be readable, creating an exploitable boundary between content and noise.
- SVG specification mastery. Understanding how SVG paths work, particularly the nuances of
ZMcommands and coordinate systems, allowed me to surgically manipulate the document structure rather than relying on brute-force image processing. - Pattern recognition. The “100 character threshold” wasn’t picked randomly — it emerged from analyzing the statistical distribution of path lengths across multiple samples.
- Reverse-engineering mindset. Instead of trying to “beat” the CAPTCHA, I sought to understand it. Each obfuscation technique was reversed by understanding its purpose and mechanism.
§ Why this matters
The CAPTCHA designers made a critical assumption: that visual complexity equals computational complexity. But visual complexity in SVG is just mathematics, and mathematics has patterns. By recognizing these patterns, I could distinguish between:
- Intentional content (the text that must remain readable)
- Artificial noise (the obfuscation that must appear random)
The very constraints that make CAPTCHAs solvable by humans — consistency, readability, geometric simplicity — are what made this attack possible.
§ The deeper lesson
The real intelligence in this solution isn’t in any single technique — it’s in the recognition that security through obscurity fails when the obscurity itself follows patterns. Every shadow needs a consistent offset. Every curve needs mathematical definition. Every stroke needs predictable rendering.
By understanding not just what the CAPTCHA was doing but why and how, I could create a solution that feels almost inevitable in hindsight. The CAPTCHA’s own requirements for human solvability became the blueprint for its defeat.
The most sophisticated attack is often the one that deeply understands its target. While the CAPTCHA tried to hide in chaos, the solution found truth in patterns.